UK Caves to the Beatles, Elton John, and 400 Creatives: AI Scraping Free-for-All Is Over
Britain's plan to gift AI companies a default licence to scrape every book, song, and painting in the nation's creative output is officially dead. What comes next is a fight over who controls the data economy - and the stakes are measured in hundreds of billions.

The UK creative sector - from recording studios to publishing houses - backed by 2.4 million jobs, forced a historic government reversal on AI training data policy. (Pexels)
On March 18, 2026, UK Science Minister Liz Kendall made an admission that Silicon Valley had hoped would never come. After months of pressure from the most famous names in British culture, the government confirmed it had dropped its "preferred option" to create a broad copyright exception allowing AI companies to scrape protected material for training - with rights holders only able to stop it by opting out individually.
The reversal is one of the most significant policy retreats in the short history of AI regulation. It means that in the UK, at least for now, the default position is that AI companies cannot train on copyrighted material without a licence. The battle to establish what that licensing should look like - who pays, how much, and for what - has just begun.
The campaign that killed the proposal reads like a casting call for a British cultural hall of fame. Paul McCartney. Elton John. Coldplay. Kate Bush. Robbie Williams. Ian McKellen. Tom Stoppard. Richard Curtis. More than 400 artists, authors, musicians and directors writing directly to Prime Minister Keir Starmer. Behind them, a £146 billion creative sector that employs 2.4 million people - dwarfing the AI sector's 86,000 jobs and £12 billion contribution.
The numbers alone should have made the policy untenable from the start. They didn't, until the names attached to them made it politically impossible.

The eighteen-month fight from the government's original consultation to the March 2026 reversal.
What the Government Actually Planned - and Why It Was Radical

Copyright law has been the frontline of the AI industry's expansion - and the UK's proposed exception would have been among the world's most permissive. (Pexels)
To understand why the retreat matters, you need to understand how aggressive the original proposal was. In late 2024, the UK government published a consultation that included plans to create what is called a "text and data mining" (TDM) exception to copyright law. Under this framework, AI companies could ingest any legally accessible copyrighted material for training purposes - books, music, film scripts, journalism, illustrations, code - without paying for it or asking permission.
The only way for a rights holder to stop this would be to actively opt out. Every individual artist, publisher, author, musician, or news organisation would have had to go through the process of registering their objection to specific AI companies scraping their specific work. Given the scale of AI training operations - models consuming billions of documents across millions of sources - this opt-out would have been practically unenforceable for most creators.
Critics called it what it was: a retroactive legalisation of copyright theft, dressed up as progressive AI policy. The House of Lords Communications and Digital Committee, reporting in March 2026, put it bluntly: the proposal "would create a scenario where a small number of US-based firms get the benefit and the harms to British creators grow."
"Copyright law is not broken, but you can't enforce the law if you can't see the crime taking place. Transparency requirements would make the risk of infringement too great for AI firms to continue to break the law." - Open letter to PM Keir Starmer, signed by 400+ UK creatives including Paul McCartney and Elton John, May 2025
The key phrase there is "US-based firms." That's not incidental framing - it goes to the heart of who benefits from the policy and who pays. OpenAI, Google, Meta, Anthropic, and Microsoft are not British companies. The creative content they wanted to train on - the Beatles catalogue, JK Rowling's novels, the BBC's archive, the works of every British artist ever photographed - is. The proposed exception would have transferred significant economic value from one side of the Atlantic to the other, for free, by government decree.
This is the second-order effect that the lobby groups hammered repeatedly: the proposal wasn't just about copyright, it was about which country captures the economic upside of the AI data economy. If British creative work trains American AI models for free, British creators lose licensing revenue, British AI startups lose a competitive advantage in high-quality training data, and the UK permanently weakens the asset that has made its creative sector one of the most valuable per capita in the world.
The Coalition That Changed the Calculation

The music industry led the charge - with artists like McCartney, Elton John, and Coldplay lending global profiles to the campaign. (Pexels)
The creative industries have fought technology companies over intellectual property before - the battles with Napster, with YouTube over ContentID, with streaming services over royalty rates. Those fights took years and yielded partial victories at best. This one moved faster, in part because the coalition was broader and more culturally visible than anything before it.
In May 2025, more than 400 leading UK arts and media professionals signed a letter directly to Keir Starmer calling for an amendment to the Data (Use and Access) Bill. The list included the kind of names that generate front pages: Paul McCartney, Elton John, Coldplay, Kate Bush, Robbie Williams, Ian McKellen, Tom Stoppard, Antony Gormley, and Richard Curtis.
But the coalition went well beyond individual artists. The Financial Times signed it. The Daily Mail signed it. The National Union of Journalists signed it. This was not a niche complaint from a few worried musicians - it was a coordinated signal from the entire UK cultural and media establishment that the policy was politically toxic.
Baroness Beeban Kidron, who has championed digital rights in the House of Lords for years, framed the stakes with characteristic clarity. "The UK is in a unique position to take its place as a global player in the international AI supply chain, but to grasp that opportunity requires the transparency provided for in my amendments, which are essential to create a vibrant licensing market," she said.
The argument embedded in that statement is worth unpacking. The traditional framing of the debate had been "AI needs data, creatives are blocking AI." Kidron and the coalition flipped it: the UK's creative industries are not an obstacle to AI - they are a potential competitive advantage. High-quality, curated training data from premium creative works is exactly what AI companies need, and will pay for, if they have to. Forcing a licensing market into existence is not anti-AI. It is pro-UK.
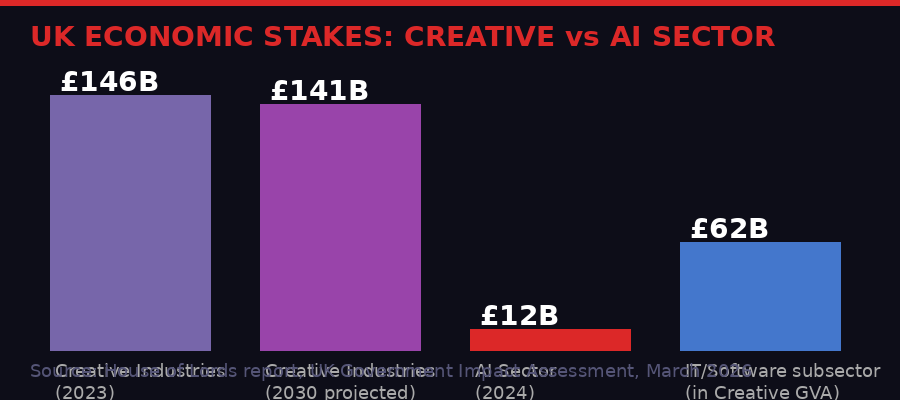
By every economic metric, the UK creative sector outweighs the domestic AI industry. The data makes the government's original proposal look like a strange choice. (BLACKWIRE)
The Policy U-Turn: What Kendall Actually Said

Westminster reversed course after sustained pressure from both the Lords and a historic alliance of British creatives. (Pexels)
On March 18, Science Minister Liz Kendall issued a written statement to Parliament that officially killed the opt-out exception plan.
"We have listened. We have engaged extensively with creatives, AI firms, industry bodies, unions, academics, and AI adopters, and that engagement has shaped our approach. This is why we can confirm today that the Government no longer has a preferred option." - Science Minister Liz Kendall, written statement to Parliament, March 18, 2026
The published impact assessment accompanying the statement makes the numbers explicit. It cites OECD estimates that AI adoption could add 0.4 to 1.3 percentage points to productivity, translating to £55 billion to £140 billion in additional UK gross value added by 2030. The assessment itself flags these as "highly uncertain."
Compare that with the creative industries' current contribution: £146 billion in GVA in 2024, with £62 billion - 42 percent of the total - coming from IT software and computer services, which itself includes AI services. The argument that weakening copyright protections would accelerate AI adoption enough to offset the damage to the creative sector was always speculative. The government finally acknowledged that speculation isn't worth the political cost.
What replaces the abandoned opt-out plan is, at this stage, a collection of intentions rather than firm policy. The government's report proposes working with industry experts to "develop best practice on input transparency," keeping "market-led licensing approaches under review," and monitoring litigation around AI and copyright in the UK and elsewhere. A Creative Content Exchange (CCE) is being developed to test commercial licensing models, with an operational pilot platform expected in the summer of 2026.
That last item is the critical one. The CCE is designed to be the infrastructure through which AI companies can actually pay for access to UK creative content at scale. If it works, it creates a functioning market. If it doesn't, the UK will end up with the worst of both worlds: an AI sector hamstrung by legal uncertainty and a creative sector still uncompensated for past use of its work.

The before and after of UK AI copyright policy - the shift from automatic permission to requiring licensing represents a fundamental change in where the default power sits. (BLACKWIRE)
Why This Is Harder Than It Looks: The Technical Reality of AI Training

AI training infrastructure ingests data at a scale that makes traditional licensing frameworks almost impossible to retrofit. (Pexels)
The government's new direction sounds clean on paper. In practice, the technical architecture of how large language models are trained creates enormous complications that no licensing framework has yet solved.
Modern AI models are trained on datasets that can contain trillions of tokens - the basic unit of text that models process. Common Crawl, one of the primary sources for web-scraped training data, contains petabytes of content from billions of web pages. Models like GPT-4, Gemini, and Claude were trained on variants of these massive aggregated datasets, often combined with curated high-quality sources like books, code repositories, and specialist publications.
The challenge for any licensing regime is attribution at this scale. When researchers at the University of Washington published a paper in January 2026 finding that probing commercial AI models could surface entire Harry Potter chapters verbatim, it confirmed what the creative industries had suspected: the training data wasn't just statistically influencing outputs, it was being memorised. Yet identifying exactly which training documents contributed to which outputs - and therefore who is owed what - remains an unsolved computer science problem.
This is where the transparency requirement that Baroness Kidron championed becomes essential. Before you can build a licensing market, you need to know what was used. The amendment she backed in the Data (Use and Access) Bill would have required AI companies to declare which individual works they had ingested. Without that disclosure, rights holders are negotiating in the dark - they cannot verify whether their work was included, cannot estimate the value of their contribution, and cannot enforce any eventual licensing deal.
Some AI companies have moved toward voluntary disclosure. OpenAI and Google have both published high-level information about training data sources. But "high-level information" is not the same as the granular disclosure that would support a real licensing market. Meta's alleged use of LibGen - a pirated books database containing millions of copyrighted texts - without disclosure is the industry's cautionary tale. The Atlantic's investigation in March 2025 found evidence linking Meta's training data to the LibGen archive, a finding that triggered a wave of litigation in the US and UK alike.
The lawsuit ecosystem is itself part of the UK government's calculation. Kendall's statement explicitly said the government would monitor "how secondary liability may apply to imported AI models placed on the UK market." That phrase - "imported AI models" - is significant. Most AI products used in the UK are trained abroad. If a US-trained model scraped British content without authorisation, and that model is then sold in the UK, what are the rights holder's remedies? The answer is currently unclear, and the government is watching US courts for precedent before committing to an answer.
The International Dimension: A Patchwork of Laws and a Race to the Bottom

Different countries have taken radically different stances on AI training data - creating a patchwork that AI companies can exploit through jurisdictional arbitrage. (Pexels)
The UK's reversal did not happen in a vacuum. It is part of a global pattern of copyright regimes cracking under pressure from the AI industry, then fighting back as the economic and political costs become clear.
Japan currently operates the most permissive AI training data regime in any major economy. Under Japanese law, text and data mining for any purpose - including commercial AI training - is broadly permitted without consent or compensation. Japanese AI companies have pointed to this as a competitive advantage. Critics counter that it has primarily benefited foreign AI companies that can train on Japanese content at no cost.
The United States has proceeded on a different theory: fair use. American AI companies have argued in multiple court cases that training an AI model on copyrighted content qualifies as transformative use and therefore does not require a licence. Courts have been increasingly sceptical. In April 2025, the US Copyright Office published a report concluding that AI model training "sometimes breach copyright" and went beyond existing fair use doctrine. The office's director was reportedly fired the next day, in a development that Washington observers read as a signal that the Trump administration intended to favour AI companies in the dispute.
The European Union occupies a middle position. The EU AI Act and accompanying copyright directives allow text and data mining with an opt-out mechanism - similar to what the UK just abandoned - but with significantly more enforcement teeth and transparency requirements than the UK's original proposal contemplated. EU data protection law also gives rights holders stronger procedural remedies than UK law currently provides.
What this means in practice is that the global AI data economy is being shaped by jurisdictional arbitrage. AI companies can choose where to train their models, and they will do so with legal risk in mind. A UK that required payment for British content would push training activity to Japan or to US servers. That outcome is not necessarily bad for UK creators - it might mean foreign companies simply pay for access rather than training on uncontrolled scraped copies - but it is not guaranteed.

The UK's reversal marks a notable tightening in a world where most jurisdictions still lean permissive on AI training data rights. (BLACKWIRE)
The Jobs Question: Who Gets Disrupted, and by Whose Consent

The creative industries argument was never just about money. It was about the right to be consulted before your work is used to automate your job. (Pexels)
The deepest tension in the AI copyright debate is not purely about money. It is about the sequence of disruption: AI companies trained on creative work to build systems that can now produce imitations of that creative work, competing commercially with the original creators, without those creators' knowledge, consent, or compensation. The House of Lords committee captured it precisely.
"Photographers, musicians, authors and publishers are seeing their work fed into AI models which then produce imitations that take employment and earning opportunities from the original creators. AI may contribute to our future economic growth, but the UK creative industries create jobs and economic value now." - Baroness Barbara Keeley, House of Lords Communications and Digital Committee, March 2026
The 2.4 million people employed by the UK creative sector are not all superstars. The letter to Starmer had household names at the top of the list, but behind them are the illustrators, session musicians, freelance journalists, translators, voice actors, and stock photographers whose livelihoods are threatened by AI systems trained on their work. These are not people with the resources to file individual copyright complaints or negotiate directly with OpenAI.
The opt-out mechanism was particularly toxic for this group. An illustrator who has sold work through stock photo agencies, or a translator who has contributed to published books, would have had to individually track which AI companies were scraping which platforms and register objections - a bureaucratic burden that would have been functionally impossible for most sole traders and small businesses. The system would have effectively protected only the large media organisations and rights societies with legal teams capable of doing it.
The UK government's pivot toward a market licensing approach at least acknowledges this problem. Rather than requiring individual rights holders to opt out, a CCE-style exchange could aggregate rights and negotiate collectively. Publishing bodies, music licensing organisations like the PRS, and news publishers' associations could negotiate on behalf of their members. This is the model the music industry uses for broadcast royalties, and it works - imperfectly, but it works.

The employment gap between the creative sector and the AI sector makes the government's original position hard to defend. The AI sector employs less than 4% as many people as creative industries. (BLACKWIRE)
What the AI Companies Actually Want - and What They'll Accept

AI companies have never claimed to want to harm creators - but their preferred policy positions suggest a different set of priorities. (Pexels)
It would be a mistake to read this as a simple story of good creators versus bad AI companies. The situation is more complex, and the AI industry's actual stated position is worth examining carefully.
Major AI companies have consistently said they support transparency and are open to licensing frameworks - in principle. In practice, their lobbying has consistently favoured broad exceptions that minimise what they have to pay and maximise their operational flexibility. The pattern is familiar from the music industry's battles with streaming: a stated commitment to "fair compensation for artists" alongside sustained effort to delay, dilute, or derail any mechanism that actually requires paying that compensation.
OpenAI, for its part, has signed data licensing deals with several major publishers, including News Corp, the Associated Press, and the Financial Times. These deals provide some model for what a broader licensing regime could look like. The AP deal, announced in 2023, gave OpenAI access to AP's news archive in exchange for an undisclosed fee. The News Corp deal, reported at $250 million over five years, is the largest publicly disclosed content licensing agreement with an AI company to date.
But these deals cover news content. The music industry, visual art, literary fiction, and independent creative work remains largely unlicensed. The music industry in particular has been vocal: the RIAA and UK Music have both argued that AI-generated music trained on copyrighted recordings constitutes infringement, a position that several ongoing lawsuits will eventually force courts to rule on.
The CCE pilot that the UK government is backing for 2026 is designed to test whether a functioning licensing exchange is technically and economically viable. If AI companies participate genuinely, it could create the infrastructure for a fair and scalable system. If they drag their feet - as the music industry suspects they will - it will demonstrate that voluntary licensing doesn't work and force the question of mandatory licensing back onto the political agenda.
The Data That Wasn't There: What "Highly Uncertain" Means for Policy
One of the most revealing details in the UK government's March 19 impact assessment is the consistent caveat attached to its AI productivity estimates. The OECD's projected £55 billion to £140 billion in additional UK GVA from AI adoption is described as "highly uncertain." Not uncertain - highly uncertain.
That uncertainty range - a factor of more than 2.5x between the low and high estimates - reflects a real epistemic problem at the core of AI policy. The productivity benefits of AI are, as of early 2026, mostly theoretical. They depend on widespread adoption across industries, successful integration into workflows, skills development across the workforce, and a technology that has to date demonstrated impressive capabilities in narrow tasks while struggling with reliability, hallucination, and safety at scale.
The creative industries' contribution, by contrast, is measured. £146 billion, 2.4 million jobs, a track record of growth and export success. You don't need to speculate about it. The UK chose to protect the certain thing over the uncertain projection, which is unusual in tech policy - governments typically trade certainty for growth promises, often without requiring proof.
This is partly a function of how visible the coalition was. McCartney and Elton John are not abstractions. The projected productivity gains from AI adoption are. When the trade-off is between real and famous people losing real income today versus hypothetical economic gains from technology that may or may not deliver on its promises, the political math is not complicated.
It is also, though, a genuine signal that the UK is attempting to position itself as a jurisdiction where high-quality data is treated as an asset rather than given away. The emphasis in the CCE plan on licensing models and transparency standards is consistent with building a data economy where British content has traceable value rather than being absorbed into models and rendered economically invisible.
What Happens Next: The Fight Is Just Starting
The government's retreat is a real victory for the creative industries, but nobody involved is calling it a win. The opt-out exception is dead, but the policy vacuum it leaves is dangerous. Legal uncertainty about whether existing AI models that have already trained on UK content are liable, and whether future models must seek licences before training, is bad for both sides.
Several threads will determine how this resolves over the next two to three years.
First, the CCE pilot. If the Creative Content Exchange launches successfully in summer 2026 and demonstrates that AI companies and rights holders can agree on commercial terms at scale, it provides the model for a functioning licensing system. If it stalls - over pricing, over attribution, over what counts as "ingestion" - the political pressure for stronger legislation will build.
Second, litigation. Cases against Meta over LibGen use, against OpenAI over book training data, and against Stability AI over image scraping are working their way through courts in the US and UK. A significant ruling - particularly on whether training itself constitutes infringement regardless of the output - would reshape the landscape globally. The UK government has explicitly flagged that it is watching these cases before finalising its own framework.
Third, the EU. If the EU develops a workable mandatory disclosure and licensing regime under the AI Act, the UK will face pressure to align - both to protect UK creators from models trained in the EU on their content, and to ensure UK AI companies face comparable rules to their European competitors.
Fourth, the AI companies themselves. The political calculus changes if major AI companies proactively engage with the CCE, sign licences, and demonstrate that the system can work. It changes further if the next generation of AI development requires even more data, or better data, pushing companies back toward negotiation rather than extraction.
"We cannot let mass copyright theft inflict damage on our economy for years to come. Transparency over AI inputs will unlock tremendous economic growth, positioning the UK as the premier market for the burgeoning trade in high-quality AI training data." - Lord Brennan of Canton, House of Lords, 2025
That framing - the UK as "the premier market for high-quality AI training data" - points at where the creative industries want to go. Not blocking AI development, but inserting themselves as a necessary, paid-for component of it. Whether that aspiration becomes reality depends on whether the government can build the infrastructure to make it work, and whether AI companies decide that paying for premium British content is worth less than lobbying against the obligation to do so.
For now, the artists won a defensive battle. The offensive one - turning "we won't let them take it for free" into "they will pay us for it" - is considerably harder. And the tech industry, which has been down this road with music, journalism, and photography before, knows how to play the long game.
Key Facts
- March 18, 2026: Science Minister Liz Kendall confirms the government "no longer has a preferred option" for a broad TDM exception to copyright
- UK Creative Industries GVA: £146 billion (2024), employing 2.4 million people - 42% from IT software/computer services
- UK AI Sector GVA: £12 billion (2024), employing 86,000 people
- AI productivity estimates: OECD projects £55B-£140B additional UK GVA by 2030 from AI adoption - described in official assessments as "highly uncertain"
- Creative Content Exchange: Pilot platform planned for summer 2026 to test market-led licensing models
- 400+ signatories to the open letter to Keir Starmer included McCartney, Elton John, Coldplay, Kate Bush, Ian McKellen, Tom Stoppard, and major media organisations
- Source: The Register, March 19, 2026; UK Government Impact Assessment; House of Lords Committee Report, March 2026
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram