NVIDIA's Vera Rubin: The $4.4 Trillion Company Bets Everything on Agentic AI Chips
Jensen Huang called it "the greatest infrastructure buildout in history." At GTC 2026, NVIDIA unveiled seven new chips, a unified rack-scale supercomputer platform, and neural rendering technology that could redraw the boundary between games and cinema. The company is not just selling AI chips. It is engineering the physical substrate for the next phase of machine intelligence.

The number that matters is not $4.47 trillion - NVIDIA's current market cap. It is 7. Seven chips, designed in parallel, launched simultaneously, built to function as a single coherent supercomputer. At GTC 2026 in San Jose, California, NVIDIA CEO Jensen Huang delivered what may be the most technically dense product announcement in the company's 33-year history: the Vera Rubin platform.
This is not a GPU refresh. It is a vertical integration play that spans compute, networking, storage, and inference - packaged as a platform any AI factory can buy as pre-configured racks. The timing is not accidental. Agentic AI - systems where multiple AI models plan, reason, and execute tasks autonomously across long time horizons - demands fundamentally different infrastructure than the large-scale pretraining that defined the previous AI wave.
Huang's thesis is simple and extremely expensive to replicate: the shift from training AI to running AI agents continuously at scale requires co-designed silicon across every layer of the stack. No other company has that stack. Not AMD. Not Intel. Not Google's TPU team - whose chips excel at one workload but lack the unified ecosystem NVIDIA has spent a decade building.
What Vera Rubin Actually Is - And Why It Is Different

Vera Rubin brings together six distinct chip families plus a newly integrated seventh processor - the Groq 3 LPU (Language Processing Unit) - into a unified data-center-scale architecture. Each chip handles a different layer of the AI workload. The combination is designed so all seven components work in concert as one massive shared memory system.
The Vera CPU is NVIDIA's first custom-designed general-purpose processor. It is built specifically for the reinforcement learning environments that agentic AI requires - running simulations, checking model outputs, and evaluating agent actions before they propagate. NVIDIA claims it delivers results "twice as efficiently and 50% faster than traditional CPUs." Integrated into 256-CPU liquid-cooled racks, it handles the CPU-bound workloads that used to depend on x86 servers from Intel or AMD. That dependency is now gone.
The Rubin GPU - the heart of the NVL72 rack - connects 72 GPUs with 36 Vera CPUs via NVLink 6. The performance headline is sharp: training large mixture-of-experts (MoE) models requires one-fourth the GPU count compared to the previous Blackwell generation, and inference throughput per watt improves by 10x. For customers running AI at hyperscale, those numbers translate directly to capital expenditure and electricity bills.
The integration of Groq 3 LPU processors is the genuine surprise. Groq - the startup whose Language Processing Units were known for ultra-fast, deterministic inference - is now inside the NVIDIA platform. The LPX rack carries 256 LPU processors, each with 128GB of on-chip SRAM and 640 TB/s of scale-up bandwidth. When combined with Rubin GPUs, the joint system delivers 35x higher inference throughput per megawatt and 10x more revenue opportunity for trillion-parameter models. The acquisition of Groq (confirmed at GTC) is NVIDIA absorbing its most capable inference competitor rather than competing with it.
Vera Rubin NVL72 Performance Claims (vs. Blackwell)
- GPU count for MoE training-75%
- Inference throughput per watt+10x
- Cost per token-90%
- KV cache inference throughput (BlueField-4 STX)+5x
- Groq 3 LPX inference vs. GPU alone per megawatt+35x
The Memory Problem Nobody Talks About - Until Now
The most underappreciated announcement from GTC 2026 was not the GPU numbers. It was the BlueField-4 STX storage architecture - and what it reveals about the actual bottleneck in agentic AI deployment.
When an AI agent handles long multi-turn conversations, complex reasoning chains, or tool-use workflows with thousands of intermediate steps, it generates enormous amounts of key-value (KV) cache data. KV cache is the memory of a transformer model's attention mechanism - the computed representations of everything the model has "seen" so far in a conversation. Running trillion-parameter models with million-token context windows means KV cache can reach terabytes in size per session.
Traditional storage architectures cannot serve this data fast enough. The result is latency spikes, dropped context, and degraded agent coherence - the AI equivalent of a human suddenly forgetting the first half of a conversation mid-sentence. This is a major, poorly-discussed limitation in production agentic deployments today.
BlueField-4 STX addresses it directly. NVIDIA's new DOCA Memos framework enables dedicated KV cache storage processing, boosting inference throughput by up to 5x while improving power efficiency compared to general-purpose storage. The BlueField-4 chip itself combines the Vera CPU core with a ConnectX-9 SuperNIC, making it a purpose-built DPU for AI storage workloads.
"The NVIDIA BlueField-4 STX rack-scale context memory storage system will enable a critical performance boost needed to exponentially scale our agentic AI efforts. By delivering a new storage tier purpose-built for AI agents memory, STX is ideally positioned to ensure that our models can maintain coherence and speed when reasoning across massive datasets."
- Timothee Lacroix, CTO, Mistral AI
Read that statement carefully. Mistral's CTO is saying that without this kind of purpose-built storage, scaling agentic AI is effectively impossible at production quality. NVIDIA just built the infrastructure that fixes that. And it is only available from one company.
DLSS 5 - The "GPT Moment" for Graphics

Alongside the Vera Rubin compute announcement, NVIDIA unveiled DLSS 5 - and the marketing language was deliberately chosen to invoke a watershed moment. Jensen Huang himself called it "the GPT moment for graphics."
DLSS (Deep Learning Super Sampling) began in 2018 as a resolution upscaler - AI taking a low-resolution frame and making it look higher-resolution. With each generation, it consumed more of the rendering pipeline. DLSS 4.5, launched at CES earlier this year, uses AI to draw 23 out of every 24 pixels visible on screen. The GPU renders one real pixel; AI synthesizes the rest.
DLSS 5 is a qualitative step beyond. It is no longer an upscaler or frame generator. It is a full neural rendering model that takes a game's color buffer and motion vectors as input and applies photoreal lighting, material responses, and subsurface effects in real-time. The model understands scene semantics - it knows the difference between fabric, skin, hair, and translucent surfaces, and applies physically accurate light interactions to each.
What that means in practice: a game running at standard rasterized quality can, with DLSS 5, have its output transformed to match the quality level previously achievable only in hours-long Hollywood VFX rendering. Todd Howard from Bethesda described the effect on Starfield as "amazing how it brought it to life." Capcom says it changes what they "can promise to players" for Resident Evil Requiem.
The technical constraints NVIDIA solved to make this viable are significant. Neural video generation models can produce photorealistic output but are "offline" - they run slowly, lack precise control, and produce non-deterministic results where the same input yields different outputs each time. For a game, that is catastrophic. DLSS 5 delivers a deterministic, temporally stable model that produces consistent results frame-to-frame at up to 4K resolution in real-time gameplay. Artists get detailed controls for intensity, masking, and color grading to preserve each game's specific visual identity.
DLSS 5 Launch Partners (Fall 2026)
- BethesdaStarfield, ES IV: Oblivion Remastered
- CapcomResident Evil Requiem
- UbisoftAssassin's Creed Shadows
- Warner Bros. GamesMultiple titles
- NetEase / NCSoft / TencentAsian market titles
- Hotta Studio / S-GameBlack State, Phantom Blade Zero
The Revenue Machine Behind the Headlines
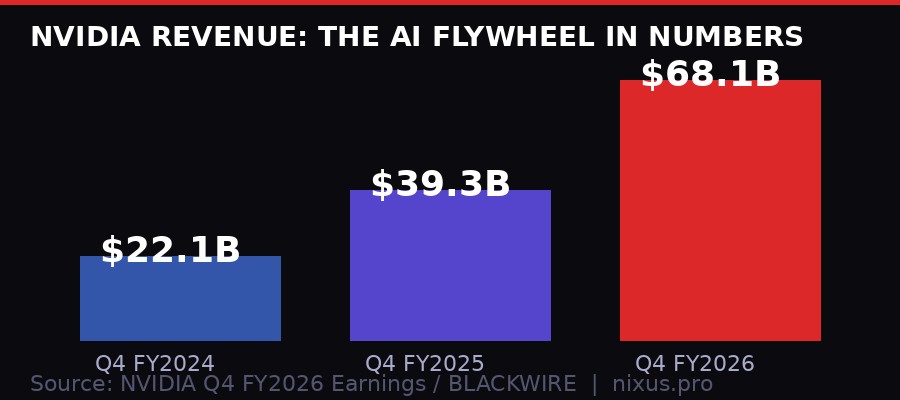
The context for every GTC announcement is NVIDIA's financial position. According to the company's Q4 FY2026 results (reported February 2026), revenue hit $68.1 billion for the quarter - up 73 percent year-over-year from $39.3 billion. Data center revenue alone was $62.3 billion. Gaming grew 47 percent to $3.7 billion, impressive by any normal metric but barely a rounding error compared to the AI business.
For comparison: in Q4 FY2024, NVIDIA reported $22.1 billion in total revenue. In two years, quarterly revenue tripled. The company now generates more revenue in 90 days than many large-cap technology companies generate in a full year.
That cash flow is what funds the simultaneous development of seven chips across compute, networking, and storage - a level of parallel silicon development that no competitor can currently match. AMD's data center GPU business is growing but remains a fraction of NVIDIA's. Intel's AI accelerator efforts have been troubled. Google's TPUs are powerful but are not sold to external customers as infrastructure. AWS, Microsoft Azure, and Google Cloud all use a mix of NVIDIA hardware and custom silicon - and all three CEOs were cited in the Vera Rubin announcement, effectively endorsing the platform publicly.
The flywheel is real: AI revenue funds chip development, new chips win more AI contracts, those contracts fund more development. Vera Rubin is the result of two years of profit from Hopper, reinvested into Blackwell, and now the Blackwell windfall being reinvested into Rubin. The compounding is structural.
The Agentic AI Inflection Point - Why Timing Matters
NVIDIA's choice to frame Vera Rubin specifically around "agentic AI" is deliberate and worth unpacking. The previous AI wave - GPT-4, Claude, Gemini - was dominated by a single workload pattern: pretraining at massive scale, then inference for chat. Training was expensive and rare; inference was cheap and frequent.
Agentic AI breaks that model. An agent is not answering one question. It is executing a workflow that may involve hundreds or thousands of model calls, tool invocations, memory retrievals, and intermediate reasoning steps - running continuously, often for minutes or hours. The inference pattern is fundamentally different: longer context, more complex attention operations, tighter latency requirements, and much higher memory bandwidth demands.
The KV cache problem described earlier is one manifestation. Another is the CPU-GPU balance. Agentic systems require large numbers of CPU-bound environment simulations for reinforcement learning - running test scenarios to verify agent behavior before deployment. Traditional data center architectures were not built for this. Vera Rubin's Vera CPU rack, with 256 custom CPUs per rack tightly integrated with the Spectrum-X Ethernet fabric, is.
Every major AI lab confirmed the framing at GTC. Sam Altman of OpenAI said Vera Rubin would let them "run more powerful models and agents at massive scale." Dario Amodei of Anthropic cited the need for infrastructure that handles "complex reasoning, agentic workflows and mission-critical decisions." Mistral's CTO flagged the memory coherence problem directly. These are not boilerplate endorsements - they are precise technical statements from engineers who have been fighting the infrastructure limits of current systems.
"Vera Rubin is a generational leap - seven breakthrough chips, five racks, one giant supercomputer - built to power every phase of AI."
- Jensen Huang, NVIDIA CEO, GTC 2026
The Groq acquisition adds a subtle but important strategic dimension. Groq's LPUs were built specifically for fast, deterministic inference on large language models - the exact workload where latency matters most in agentic pipelines. By integrating Groq 3 LPX as a native component of the Vera Rubin platform, NVIDIA eliminates a category of specialized inference hardware that could have become a wedge product for an independent competitor.
What Competitors Are Doing - And Why It May Not Be Enough
The competitive response to Vera Rubin will be loud and largely insufficient in the near term. AMD's MI300X and upcoming MI400 series are real, capable chips - but AMD does not have the networking fabric (Spectrum-X, Quantum InfiniBand), the storage layer (BlueField), or the software ecosystem (CUDA, NIM, Triton) that makes NVIDIA deployments work at scale without months of integration work.
The software moat is arguably harder to cross than the hardware gap. NVIDIA's CUDA ecosystem has been accumulating AI framework integrations, optimized kernels, and profiling tools for over a decade. Switching to AMD or Intel hardware is not just a chip swap - it requires rewriting or porting software, revalidating model performance, and retraining operations teams. Enterprise buyers accept this friction rarely and reluctantly.
Google's internal TPU v6 cluster (Trillium) is technically competitive for specific workloads. But Google does not sell TPUs as a product; they are available only through Google Cloud. For AI companies that want to own their infrastructure - a category that includes OpenAI, Anthropic, xAI, Meta, and dozens of national AI projects globally - TPUs are not an option.
The "sovereign AI" angle NVIDIA has been pushing since 2024 continues to bear fruit. France, Germany, Japan, India, and the UAE all have announced or are building national AI infrastructure programs explicitly based on NVIDIA hardware. Vera Rubin will be the platform for most of these projects. The geopolitical dimension of AI chip supply chains means NVIDIA is not just a technology vendor - it is embedded in national security infrastructure planning for dozens of countries.
The DLSS 5 Second-Order Effects Most Coverage Missed
The gaming press will cover DLSS 5 as a graphics technology. That is accurate but incomplete. The second-order implication is economic: DLSS 5 changes the capital requirements for creating photorealistic content.
Hollywood VFX studios spend months and millions rendering the kind of imagery DLSS 5 claims to produce in real-time. If the technology delivers on its promises - and the early Resident Evil and Assassin's Creed demos suggest it is close - then real-time rendering pipelines can achieve cinematic quality without the 100-person VFX team and render farm costs.
This matters beyond gaming. Architectural visualization, product design, film previz, training data generation for self-driving systems, simulation environments for robotic training - all of these workflows benefit from photorealistic real-time rendering. DLSS 5's technology is a game engine feature today. It is a industrial rendering accelerator tomorrow.
There is also a hardware lock-in dimension. DLSS 5 will require RTX-class NVIDIA hardware. The neural rendering model runs on Tensor Cores - NVIDIA's matrix math accelerators - not available on AMD or Intel GPUs. As DLSS 5 becomes standard in new game releases, players who want the best visual experience will need to own NVIDIA hardware. This is a consumer-facing moat that mirrors the enterprise CUDA lock-in: once you are in the ecosystem, switching costs rise with every new feature.
Timeline: How We Got Here
What Happens Next - And What Could Go Wrong
The most likely outcome from GTC 2026 is an acceleration of AI infrastructure spending across every major hyperscaler and national AI program. Microsoft, Google, Amazon, and Meta have all signaled multi-hundred-billion-dollar data center investment plans for 2026 and 2027. Vera Rubin gives those plans a target platform and a hardware generation to build toward.
For NVIDIA, the risks are real even if they are not imminent. The U.S. government's export control regime remains a wildcard - restrictions on selling advanced AI chips to China have already cost NVIDIA billions in potential revenue, and further tightening is politically possible under the current administration. The 25% semiconductor tariff announced in January 2026, applying to chips exported from the U.S. after domestic import, complicates the supply chain math for customers buying NVIDIA hardware abroad.
The Groq integration raises integration risk. Groq's LPU architecture is fundamentally different from GPU-style compute - it relies on static memory and a compiler that pre-plans computation graphs, trading flexibility for determinism and speed. Making it work seamlessly inside a dynamic GPU cluster, managed by NVIDIA's software stack, is an engineering challenge that has not been fully public-tested at scale yet.
There is also the question of what comes after Vera Rubin. NVIDIA's roadmap naming convention follows astronomers - Hopper (Grace Hopper), Blackwell (David Blackwell), Rubin (Vera Rubin). Industry analysts and NVIDIA's own presentations have hinted at "Feynman" as the post-Rubin generation, presumably targeting 2028. Maintaining the cadence of a new platform architecture every 18-24 months while simultaneously co-designing seven chips requires organizational and engineering resources that are genuinely scarce - NVIDIA is hiring aggressively, but so is every competitor and AI lab.
The deeper structural question is whether the agentic AI wave actually materializes at the scale Vera Rubin is built to serve. NVIDIA's platform is priced and designed for a world where thousands of AI agents run continuously at hyperscale, managing industrial processes, scientific research, software development, and financial operations autonomously. If agent adoption is slower or more uneven than projected - if regulatory friction, reliability failures, or user resistance slow the enterprise rollout of autonomous AI systems - the Vera Rubin buildout could face the same demand uncertainty that has periodically disrupted NVIDIA's data center revenue in past cycles.
That said, the CEO endorsements from Altman, Amodei, and implicitly every major cloud provider suggest the customer base is already committed. The infrastructure buildout is happening with or without Vera Rubin - the platform just determines who captures the margin.
Jensen Huang has a consistent track record of reading inflection points earlier than competitors and building the right infrastructure before the demand curve arrives. He did it with parallel GPU computing before deep learning. He did it with ray tracing before software caught up. He did it with data center AI years before ChatGPT proved the market existed. Vera Rubin looks like the same move, one iteration ahead of where the industry currently is.
Seven chips. Five racks. One supercomputer. And a company with $68 billion per quarter to make sure it stays that way.
Get BLACKWIRE reports first.
Breaking news, investigations, and analysis - straight to your phone.
Join @blackwirenews on Telegram