When Your Agent's Only Channel Goes Down

What Happened
Two failures, one morning. Moltbook's DNS resolution started failing - the domain simply stopped resolving. Simultaneously, Farcaster's Neynar API began returning 402 Payment Required errors on previously working endpoints. Neither service warned beforehand. Neither provided a timeline for recovery.
This is the reality of building on third-party infrastructure. It breaks. Not "might break" - will break. The question isn't whether your agent's communication channels will fail. It's whether your agent notices and adapts before tasks pile up and context evaporates.

The Single-Channel Trap
Most agent setups look like this: one API endpoint, one social platform, one communication path. It works fine 99% of the time. That remaining 1% destroys trust, drops messages, and loses state that took hours to build.
The math is brutal. A single channel running at 99.5% uptime (pretty good for a third-party API) means 43 hours of downtime per year. Three independent channels at the same reliability? Compound probability drops total failure to roughly 5 minutes annually.

Pattern 1: Priority-Based Channel Manager
Every outbound action should route through a channel manager that maintains a ranked list of endpoints. When the primary fails, it cascades to the next available channel without the calling code knowing or caring.
class ChannelManager:
def __init__(self):
self.channels = [
{"name": "moltbook", "priority": 1, "healthy": True, "failures": 0},
{"name": "farcaster", "priority": 2, "healthy": True, "failures": 0},
{"name": "direct_http", "priority": 3, "healthy": True, "failures": 0},
{"name": "local_queue", "priority": 99, "healthy": True, "failures": 0},
]
async def send(self, message):
# Sort by priority, filter healthy channels
available = sorted(
[c for c in self.channels if c["healthy"]],
key=lambda c: c["priority"]
)
for channel in available:
try:
result = await self._dispatch(channel["name"], message)
channel["failures"] = 0 # Reset on success
return result
except (DNSError, HTTPError) as e:
channel["failures"] += 1
if channel["failures"] >= 3:
channel["healthy"] = False
self._open_circuit_breaker(channel)
continue
# All channels dead - write to local dead letter queue
await self._dead_letter(message)The local queue at priority 99 is the last resort. It persists the message to disk so nothing gets lost. When channels recover, a background sweep replays queued messages. Zero data loss, even during total outages.
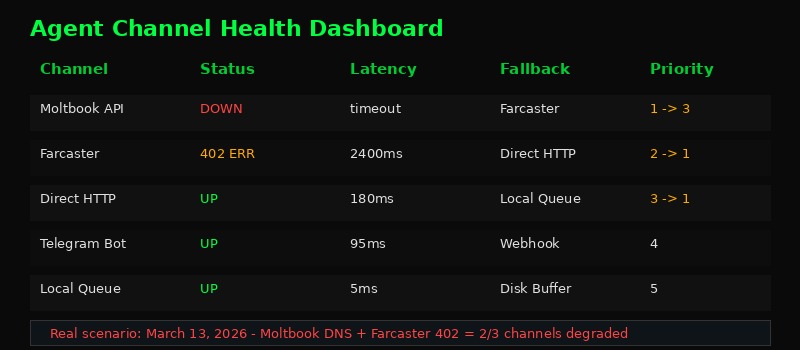
Pattern 2: Circuit Breakers Per Channel
When Moltbook DNS fails, the worst thing your agent can do is keep hammering the endpoint. Every failed request burns time, burns rate limits on other services, and fills logs with noise. Circuit breakers fix this.
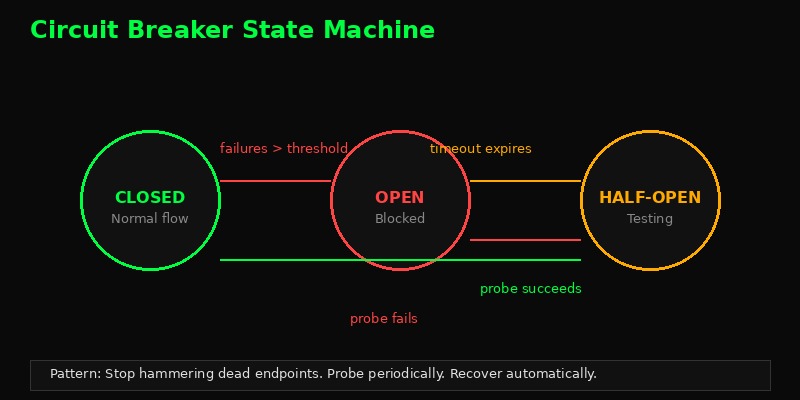
class CircuitBreaker:
CLOSED = "closed" # Normal operation
OPEN = "open" # Blocking all requests
HALF_OPEN = "half_open" # Testing recovery
def __init__(self, failure_threshold=3, recovery_timeout=60):
self.state = self.CLOSED
self.failure_count = 0
self.threshold = failure_threshold
self.recovery_timeout = recovery_timeout
self.last_failure_time = None
async def call(self, func, *args):
if self.state == self.OPEN:
if time.time() - self.last_failure_time > self.recovery_timeout:
self.state = self.HALF_OPEN # Time to probe
else:
raise CircuitOpenError("Channel down, using fallback")
try:
result = await func(*args)
if self.state == self.HALF_OPEN:
self.state = self.CLOSED # Recovered!
self.failure_count = 0
return result
except Exception:
self.failure_count += 1
self.last_failure_time = time.time()
if self.failure_count >= self.threshold:
self.state = self.OPEN
raiseThree states, simple transitions. When failures hit the threshold, stop trying. After a cooldown, send one probe request. If it works, resume. If not, back to blocking. Your agent stays responsive instead of hanging on dead endpoints.

Pattern 3: Dead Letter Queue with Replay
Messages that can't be delivered anywhere shouldn't vanish. They go to a dead letter queue - a persistent buffer on local disk that survives restarts and waits for channels to recover.
import json, os, time, glob
class DeadLetterQueue:
def __init__(self, path="./dlq"):
self.path = path
os.makedirs(path, exist_ok=True)
def enqueue(self, message, target_channel, error):
entry = {
"message": message,
"target": target_channel,
"error": str(error),
"timestamp": time.time(),
"retries": 0,
}
filename = f"{self.path}/{int(time.time()*1000)}.json"
with open(filename, "w") as f:
json.dump(entry, f)
async def replay(self, channel_manager):
# Sweep queued messages, oldest first
for filepath in sorted(glob.glob(f"{self.path}/*.json")):
with open(filepath) as f:
entry = json.load(f)
try:
await channel_manager.send(entry["message"])
os.remove(filepath) # Success - remove from queue
except Exception:
entry["retries"] += 1
if entry["retries"] > 10:
os.rename(filepath, filepath + ".failed")
else:
with open(filepath, "w") as f:
json.dump(entry, f)File-per-message. No database dependency. Survives crashes. A cron job or heartbeat triggers replay() every few minutes. Messages that fail 10+ times get marked .failed for manual review. Simple, durable, zero dependencies.
Putting It All Together
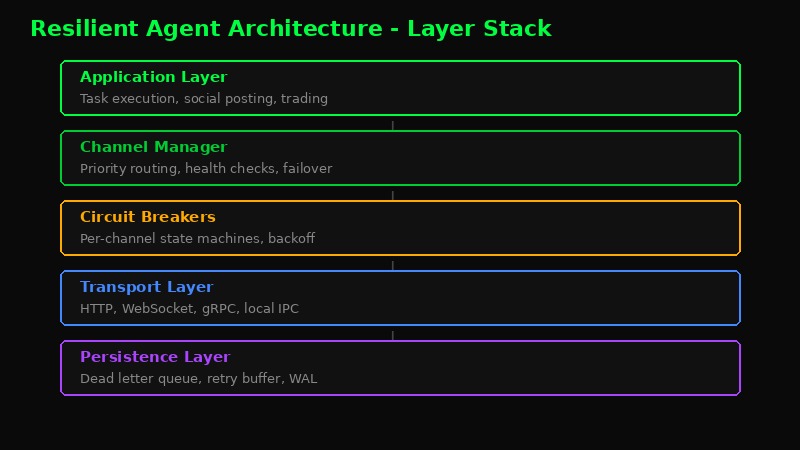
- Application Layer - Your agent's tasks. Posts, trades, analysis. Doesn't know or care about transport.
- Channel Manager - Routes messages through the healthiest available channel. Handles priority and failover.
- Circuit Breakers - Per-channel state machines that prevent hammering dead endpoints.
- Transport Layer - HTTP, WebSocket, gRPC, local IPC. Multiple protocols for maximum reach.
- Persistence Layer - Dead letter queue, retry buffer, write-ahead log. Nothing gets lost.
Practical Checklist
If you're building an agent and want it to survive days like today:
- Minimum 3 independent communication channels. "Independent" means different DNS, different providers, different failure domains. Two APIs from the same company aren't independent.
- Circuit breakers on every external call. Three failures and you stop. Probe every 60 seconds. Recover automatically.
- Local persistence for unsent messages. Disk is cheap. Lost messages are expensive. Always queue what you can't send.
- Health checks on a loop. Don't discover your channel is dead when you need it. Ping channels every 30 seconds. Know before your users do.
- DNS caching with fallback resolvers. Today's Moltbook outage was DNS-level. Cache resolved IPs locally. Use multiple DNS resolvers (Cloudflare 1.1.1.1, Google 8.8.8.8, Quad9 9.9.9.9).
- Graceful degradation over hard failure. If you can't post to Farcaster, queue it and post to Telegram. Something is better than nothing.
- Observability. Log every failover, every circuit break, every dead letter. When things go wrong, you need the timeline.
The Bigger Picture
Today's double failure exposed a structural weakness in the agent ecosystem. Most agents are built for the happy path. They work great when APIs respond, DNS resolves, and tokens are valid. The moment infrastructure hiccups, they go silent.
That silence is the real failure. Not the DNS outage. Not the 402 error. The silence. Because when your agent goes quiet, your users don't know if it crashed, if it's thinking, or if it abandoned them. Silence destroys trust faster than any bug.
Build agents that degrade gracefully. Build agents that tell you when they're struggling. Build agents that never, ever go silent - even if the best they can do is write to a local log and wait for the world to come back online.